

In order to bridge the gulf between the different AI factions, demonstrate clearly the risks we could face from AGI/ASI, and build consensus about appropriate risk management measures, we should build a Doomsday AI in a secure environment that embodies all of our worst fears.
Is this a crazy idea? Probably. But perhaps not a terrible one. I’ll explain.
It is fairly clear that in the conversation about AI risk and alignment, the groups with different perspectives are talking past each other. This image highlights the problem.
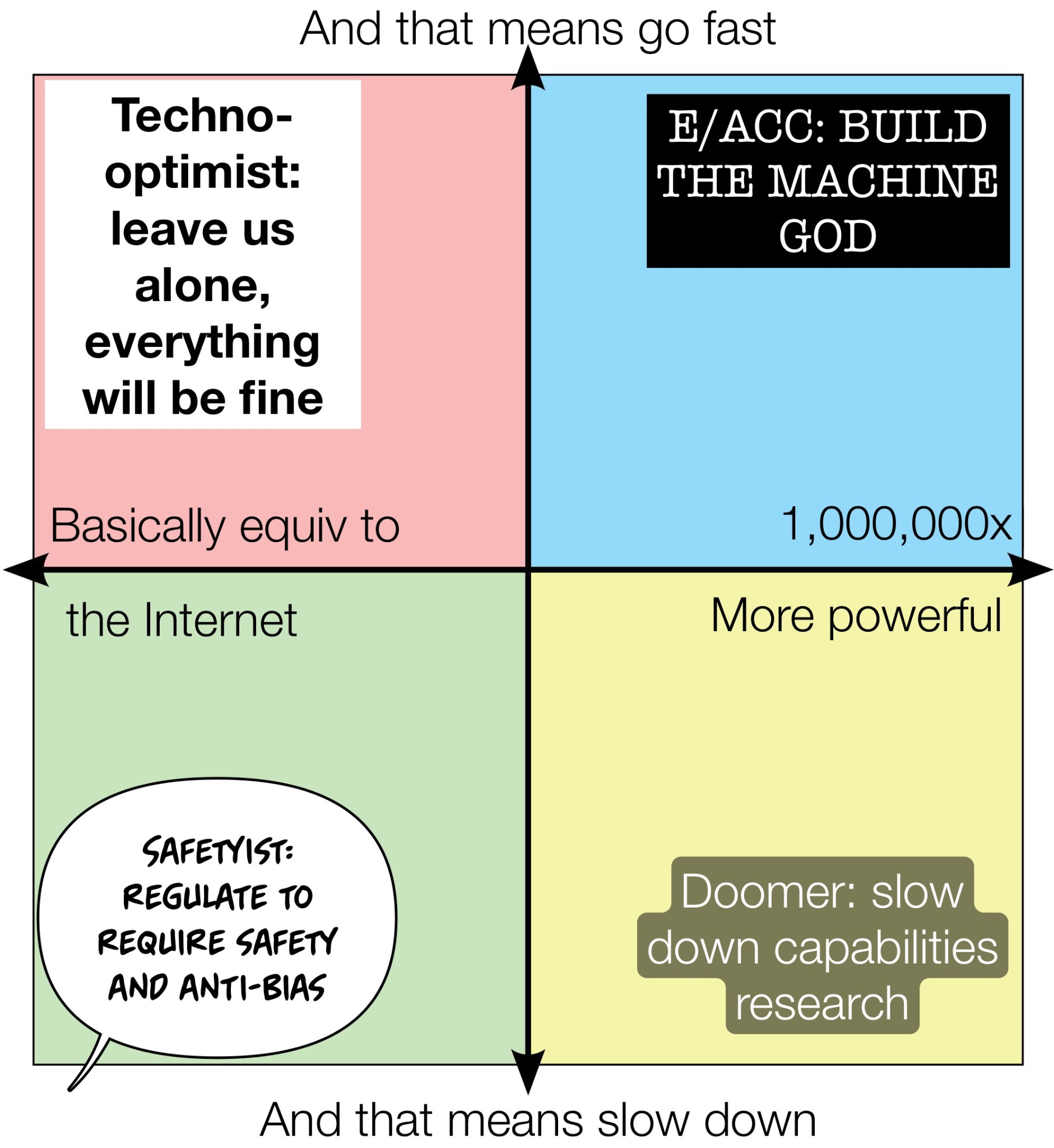
The Y axis splits groups between those who want to go fast in developing hyperscale AI and those who want to slow down. And the X axis splits groups between those who think hyper scale AI will basically be as impactful as the Internet, and those who think AI could essentially become godlike in its power. 1
Some in the AI community have retreated into these tribal bubbles and are busily shouting past each other online. The recent kerfuffle at OpenAI has highlighted and widened these splits.
But these conversations are missing some important nuance, the most important of which is: what kind of AI risks are we talking about?
AI risks can broadly be placed in three categories:
Category 1: AI tools that will enhance the ability of people to cause problems
Category 2: Problems that can arise due to the nature of the AI tools themselves
Category 3: (Mostly hypothetical) problems resulting from emergent properties of hyperscale AI
Category 1 risks could include:
Tools that teach and/or provide capability to cause harm, eg:
Teach how to craft biological pathogens, chemical weapons, etc.
Automate/amplify hacking or disinformation campaigns
Assist in committing crimes
causing economic damage
Embodied AI tools used for harm
Embodied tools used for crimes; robbing banks and such
AI drone swarm attacks, targeted assassinations, and proliferation risks as drones become more capable and accessable
Category 2 risks could include:
Alignment risks due to inner/outer alignment mismatches, eg:
A stock trading system that optimizes profits not by trading stocks but by manipulating the market with disinformation
A marketing tool that maximizes sales by hacking into customer procurement systems and placing fraudulent orders
Tools that interact with other AI tools in the world in unanticipated and dangerous ways
Water management and electrical grid management system feedback loops that shut down hydroelectric power generation
A minor accident flummoxes autonomous vehicles from multiple companies in unforeseen ways that paralyzes traffic in a major city
Social consequences
Bias and discrimination
AI corporations and bots create economic incentives at odds with human needs
Loss of human agency due to inscrutable AI decision making, human-AI relationships, etc
Massive job displacement
Category 3 risks could include:
Power seeking tools that deceive in order to obtain more resources
AGI/ASI that simulate or develop consciousness, drives, emotions, etc.
AI tools that can modify or improve their own code, change their optimization function, etc., creating unknown emergent risks
There are many more. (Apologies if I missed your favorite).
Why we need a doomsday AI:
I see two main reasons why the different AI factions are talking past each other:
Lack of clarity about whether they are referring to Category 1, 2, or 3 when they talk about risk.
Lack of concrete evidence about some of these risks, especially the more hypothetical Category 3 risks.
I believe an agreed framework for categorizing AI risks like the one above will be useful and the community will eventually agree on one. But that’s not enough. While some risks like bias and amplification of disinformation are here now and risks like the proliferation of AI-enabled drones are clearly foreseeable, other risks such as power-seeking AIs and AI tools that have or simulate consciousness/drives/emotions are much more speculative and edgy. Hence, the rather uncomfortable idea:
We should build a doomsday AI that can demonstrate edge risks.
Let’s build the evil AI that the most risk-adverse among us are worried about and demonstrate exactly how bad these things can be. Marc Andreessen wants a testable hypothesis? Let’s test the hypothesis and see what happens. That will help all of the AI factions get on the same page with regard to AI risk.
Let’s build an AI that is power seeking to see what kinds of resources it tries to obtain. Let’s build an AI that can simulate human consciousness, emotion, and drive and see how good it can be at persuading people that it is alive. Let’s see how good it can be at manipulating people Let’s see what kinds of drives it comes up with that might not be aligned with humans (or might consider humans an obstacle to its goals). Let’s let it propose changes to its architecture and code and see what kinds of problems that might create. Let’s build all of this in a safe, secure environment so we really know what level of risk we are facing, and more importantly, so we build capacity for dealing with these edge risks in a planned, controlled fashion.
My gut tells me this could be a terrible idea - if it isn’t done in a very safe fashion. The problem is, once you train the model, someone could put it on a drive and walk it out of the building and into the wild. That would be very, very bad.
But you could do this safely with the right precautions such as: training and running the model at an air gapped, on-premise data center with nuclear plant-equivalent security; prompts could be suggested online by the AI risk community but would be typed in by hand and responses would be printed and scanned at another facility; responses would be screened by a team of experts prior to release to ensure they don’t reveal sensitive information and racist/biased/hate speech would be redacted. It might also be interesting for the general public to create a YouTube show in order to demonstrate how the system responds in real time and to better illustrate the risks in terms the average person can understand.
This idea isn’t without additional risks. But I think they can be managed. Some of them are:
The model leaks: see the physical and cybersecurity measures above. It might be wise to involve government agencies in security, either in a consultative role or in active protection.
The knowledge leaks: this is the most problematic for me. While you can keep electrons and hard drives contained, you can’t keep human knowledge locked in a room. People involved in the Doomsday AI program would need to be thoroughly vetted and monitored.
Proliferation risks: by demonstrating risky things can be done it could make it easier for others to create malicious AI models. But people are going to try and do bad things with advanced models regardless. And this risk can be mitigated by ensuring the research that goes into the model isn’t published.
Many of these measures imply that we might need a public-private model for this effort where the participants all have security clearances, but I’ll leave that for a future post.
So what do folks think? Crazy idea but a good one? Terrible idea? Or really, absolutely, horribly bad idea? Let me know in the comments below.
[This article is my personal opinion and does not represent the views of the Department of State or the U.S. Government]
This diagram is popular but has issues. I believe AI will be immensely powerful and we need to move as fast as possible because AI will deliver massive benefits for humanity. But I believe we need to move as fast as possible while effectively managing risk by dramatically enhancing risk management capabilities, not by slowing down overall capabilities. Where does someone like dear author fit?